고정 헤더 영역
상세 컨텐츠
본문
728x90
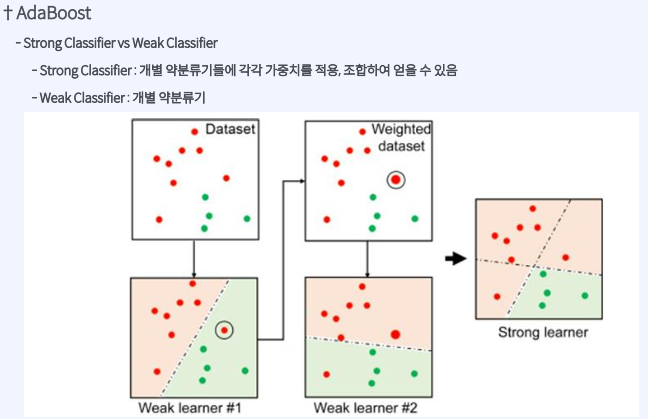
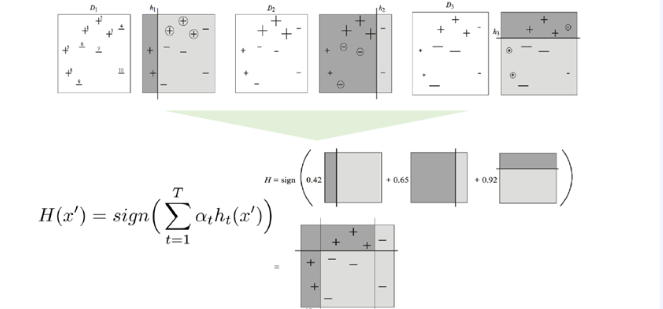
Adaboost
부스팅 계열 -reduce the bias
잘 못 맞춘 데이터 변환(change distribution of training data)
AdaBoost = Adaptive + Boosting
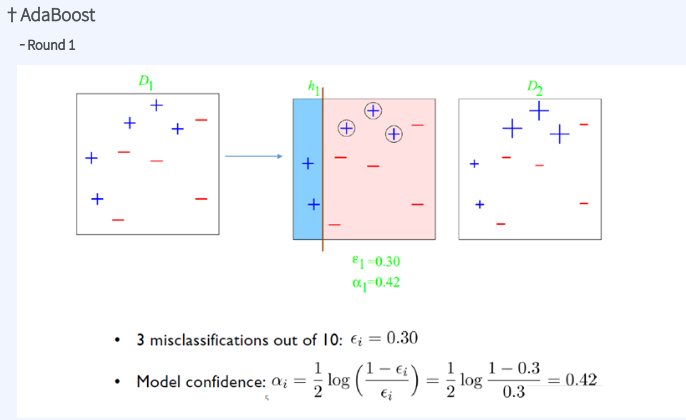
10개 중 3개를 miss class -> 엡실론 0.3

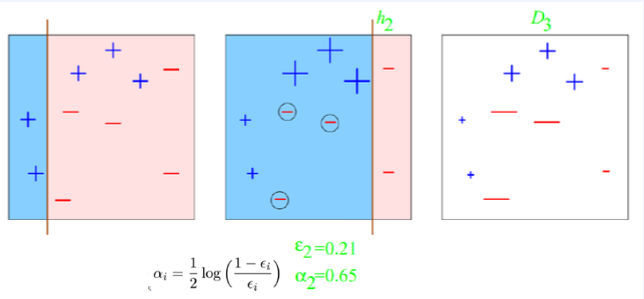
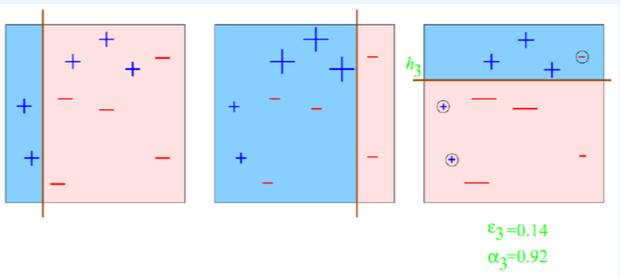
계속하여 엡실론 감소
Final Classifier = Strong Classifier
Gradient Boosting Machine
Classification 뿐만 아니라 Regression 사용 가능
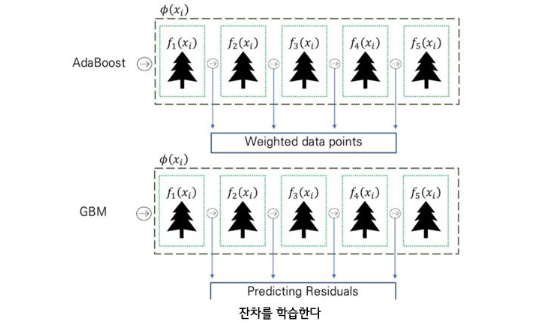
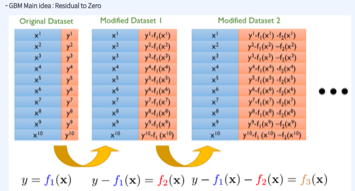
실제값-예측값 잔차를 계속하여 학습
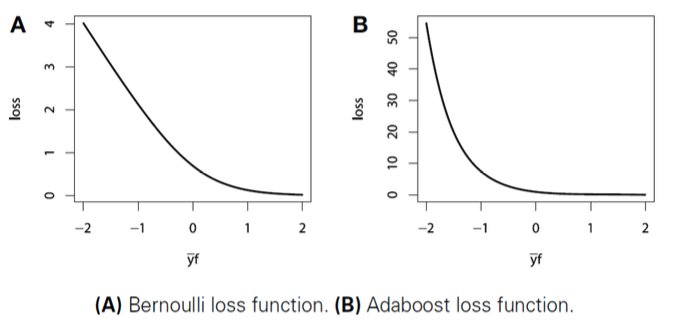
Loss Function

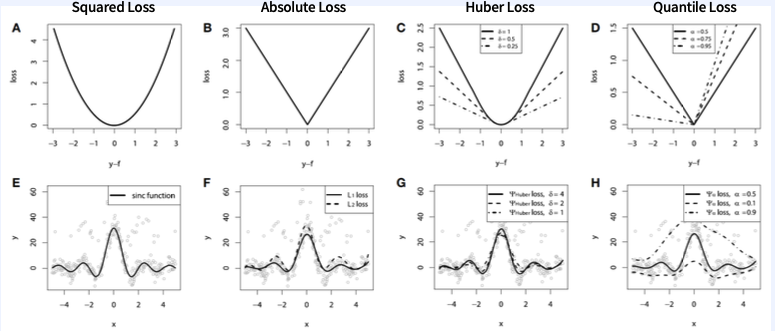

overfitting problem
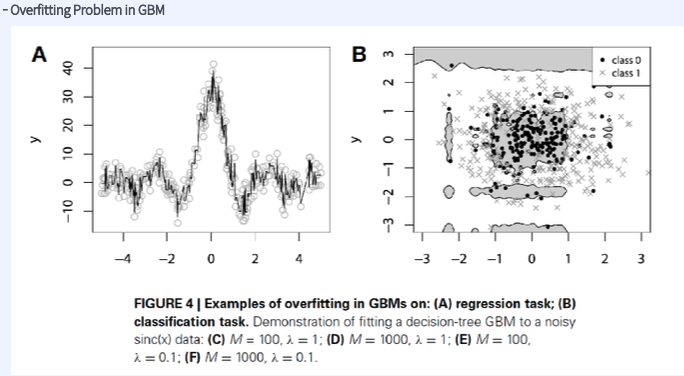
Overfitting 방지
1. Subsampling
- 복원 추출이 아닌(without replacement) Just sampling 하여 iteration 마다 data를 Sampling 하게 함
- 하지만 bagging (Bootstrap + Aggregating)도 또한 가능함
2.Shrinkage
- Using for Reduction/Shrinking the impact of each additional fitted base-leaners
(Penalty Term이랑 비슷한 개념, 조금만 반영하기)
- Better to improve a model by taking many small steps than by taking fewer large steps
3. Early Stopping
- Using the Validation Error
Feature Importance Score
- 𝑰𝒏𝒇𝒍𝒖𝒆𝒏𝒄𝒆𝒋(𝑻) : Single Tree인 T의 j 번째 Feature
※ L이 Terminal nodes라고 가정 했을 때 L-1 splits, IG : Information Gain
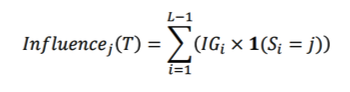
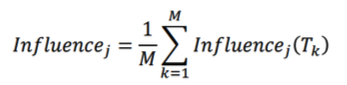
'ML' 카테고리의 다른 글
| LightGBM (0) | 2024.03.22 |
|---|---|
| XGBoost (0) | 2024.03.22 |
| Classification- Decision Tree / Random Forest Code (0) | 2024.03.21 |
| Classification- Random Forest (0) | 2024.03.20 |
| Classification- 모델 평가 및 지표 해석/ 앙상블 정의 (0) | 2024.03.20 |




