고정 헤더 영역
상세 컨텐츠
본문
728x90
머신러닝 개인과제 해설~@[공부해라..~]
머신러닝 심화강의
데이터 분리 실습
x변수 fare,sex / y변수 survived
import pandas as pd
titanic_df=pd.read_csv('/train.csv')
titanic_df.head()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test= train_test_split(titanic_df[['Fare','Sex']],titanic_df[['Survived']],
test_size=0.3, shuffle=True, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
Y값 분포 확인
sns.countplot(titanic_df, x='Survived')
stratify 층화 추출.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test= train_test_split(titanic_df[['Fare','Sex']],titanic_df[['Survived']],
test_size=0.3, shuffle=True, random_state=42, stratify=titanic_df[['Survived']])
test 데이터는 격리되어야.
데이터 전처리
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
train_df=pd.read_csv('train.csv')
test_df=pd.read_csv('test.csv')
train_df.info()
train_df.describe(include='all')
train_df_2=train_df.copy()
def get_familly(df):
df['Family']=df['SibSp']+df['Parch']+1
return df
get_familly(train_df_2)
수치형 데이터 이상치 제거
sns.pairplot(train_df_2[['Age','Fare','Family']])
train_df_2 = train_df_2[train_df_2['Fare']<512]
train_df_2.shape
train_df_2['Fare'].describe()
결측치 처리
def get_non_missing(df):
Age_mean=train_df_2['Age'].mean()
df['Age']=df['Age'].fillna(Age_mean)
df['Embarked']=df['Embarked'].fillna('5')
return df
get_non_missing(train_df_2).info()
이상치 o : standardscaler, 이상치 x: minmaxscaler
def get_numeric_sc(df):
#sd_sc:Fare, mm_sc; Family, Age
from sklearn.preprocessing import StandardScaler, MinMaxScaler
sd_sc= StandardScaler()
mm_sc=MinMaxScaler()
sd_sc.fit(train_df_2[['Fare']])
df['Fare_sd_sc']=sd_sc.transform(df[['Fare']])
mm_sc.fit(train_df_2[['Age','Family']])
df[['Age_sc','Family_sc']]=mm_sc.transform(df[['Age','Family']])
mm_sc.fit(train_df_2[['Age','Family']])
df[['Age_sc','Family_sc']]=mm_sc.transform(df[['Age','Family']])
return df
get_numeric_sc(train_df_2).describe()
범주형 데이터 인코딩
def get_catecory(df):
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
le=LabelEncoder()
le2=LabelEncoder()
oe=OneHotEncoder()
le.fit(train_df_2[['Pclass']])
df['Pclass_le']=le.transform(df[['Pclass']])
le2.fit(train_df_2[['Sex']])
df['Sex_le']=le2.transform(df[['Sex']])
oe.fit(train_df_2[['Embarked']])
embarked_csr=oe.transform(df[['Embarked']])
embarked_csr_df= pd.DataFrame(embarked_csr.toarray(), columns=oe.get_feature_names_out())
df= pd.concat([df,embarked_csr_df],axis=1)
return df
교차검증
고정된 테스트 데이터; 과적합에 취약.
데이터 셋을 여러개의 하위 집합으로 나누어 돌아가며 검증 데이터로 사용
k-fold validation
데이터가 부족할 경우 유용함. 반복학습
하이퍼 파라미터 자동적용- grid search
;모델 구성하는 값 중 임의로 바꿀 수 있는 값
데이터 분석 프로세스 정리
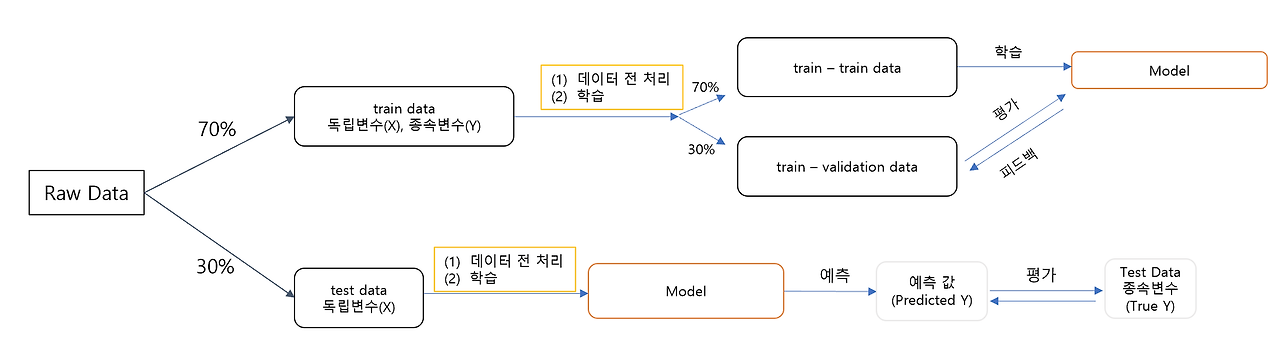
회귀/분류 모델링 심화
의사결정 나무 decisioin tree dt

불순도: 지니계수(불순도 측정방법 중 1) 0과 1사이
1-- 완전한 불순도 균등한 분포.
장점: 해석 용이/ 다중분류와 회귀 모두 적용/ 이상치에 견고, 데이터 스케일링 불필요(데이터 상대적 순서 고려하기에)
단점: 나무 성장 많이할 시 과적합 우려/ 훈련데이터에 민감, 작은 노이즈에도 구조 달라짐. 불안정성
랜덤포레스트
의사결정 나무의 과적합과 불안정성 문제 해결
배깅
bootstrapping 데이터 복원 추출. 유사하지만 다른 데이터 집단
aggregating: 데이터 예측, 분류 결과 합침
ensemble: 여러개의 모델 만들어 결과를 합침.

장점: 과적합문제 보완/이상치에 견고, 데이터 스케일링 불필요/ 변수 중요도 추출, 모델 해석 특징 파악
단점: 컴퓨터 리소스 비용 큼/ 앙상블 적용으로 어려운 해석.
K-Nearest Neighbor KNN 최근접 이웃
주변 데이터를 통해 알고 싶은 데이터 예측.
주변 k개 데이터 선정 후 거리 기준으로 가장 많은 것을 예측.
k개선정과 거리 측정.
장점:이해 쉽고 직관적/ 모집단 가정 형태 고려 않음/ 회귀 분류 모두 가능
단점: 차원 수가 많을 수록 계산량 증가/ 거리 기반 알고리즘이기에 피처의 표준화가 중요
파라미터: 모델 학습 과정에서 추정하는 내부 변수. 자동으로 결정되는 값. like 선형회귀의 가중치, 편향
하이퍼 파라미터: 기계 학습 모델 훈련에 사용하는 외부 구성변수.
좋은 결과가 나올 때가지 실험.
유클리드 거리

거리 기반 알고리즘- 단위에 민감. 따라서 표준화 필수. (스케일링)
부스팅 알고리즘
약한 학습기 여러개를 순차적으로 학습하여 잘못 예측한 데이터에 가중치 부여, 오류 개선. 강화
부스팅 알고리즘 종류
Gradient Boosting Model
경사하강법을 통해 가중치 업데이트
XGBoost
트리기반 앙상블 기법.
병렬학습 - 빠른 속도.
LightGBM
상대적 짧은 학습시간, 적은 메모리 사용량
작은데이터, 만건 이하의 경우 과적합 발생
비지도 학습
답을 알려주지 않고, 유사성을 이용해 답을 지정.
데이터를 기반으로 레이블링.
K-Means Clustering
1 k개 군집 수 설정
2 임의의 중심 선정
3 해당 중심점과 거리가 가까운 데이터를 그룹화
4 데이터 그룹의 무게 중심으로 중심점을 이동
5 중심점을 이동했기에, 다시 거리가 가까운 데이터를 그룹화. 3~5회 반복
장점: 일반적, 적용 쉬움
단점: 거리기반이기에 차원 많을 수록 정확도 떨어짐/ 반복횟수 많을 수록 시간 증가/ 몇개의 군집 선정할 지 주관적/ 평균(중심점) 이용하기에 이상치에 취약
군집 평가 지표
군집화가 잘 되어 있다: 다른 군집간의 거리는 떨어져 있고 동일한 군집끼리는 가까이
실루엣 계수
군집간의 거리가 얼마나 효율적으로 분리되어 있는지 측정
1- 근처 군집과 멀리 떨어진. 0- 가까운.
실루엣 값이 높을 수록 / 개별 군집의 평균 값의 편차가 크지 않을 수록 좋음
고객 세그멘테이션
RFM
Recency 가장 최근 구입 일에서 오늘까지의 시간
Frequency 상품 구매 횟수
Monetary value 총 구매 금액
딥러닝
자연어 처리, 이미지 처리
인공신경망.
퍼셉트론: 인공신경망의 가장 작은 단위
가중치
가중치를 변경하며 최소의 MSE(에러제곱총합평균) 도출 -- 이렇게 최소화하려는 값: 목적함수, 손실 함수 cost fuction
경사하강법: gradient descent
모델의 손실함수 최소화 위해 모델의 가중치를 반복적으로 조정하는 최적화 알고리즘
배치 경사하강/확률적 경사하강법
활성화 함수
비선형적 분류를 만들기 위해.

히든레이어
비선형적으로 변환, 데이터의 고차원적 특성 학습.
기울기 소실 문제. (인공신경망학습: 순전파/역전파 학습)
역전파 과정에서 하위 레이어로 갈수록 오차의 기울기 점차 작아져서 가중치가 거의 업데이트 되지 않음
활성화 함수(relu)로 완화.
-tensorflow
!pip install tensorflow
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
from sklearn.preprocessing import StandardScaler
weights =np.array([89,81,82,92,90,61,86,66,69,69])
heights = np.array([187,174,179,192,188,160,179,168,168,174])
model= Sequential()
dense_layer =Dense(units= 1, input_shape=[1])
model.add(dense_layer)
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
model.fit(weights,heights, epochs=100)
hidden layer 만들기
model2= Sequential()
model2.add(Dense(units=64,activation='relu', input_shape=[1]))
model2.add(Dense(units=64, activation='relu'))
model.add(Dense(units=1))
model2.compile(optimizer='adam',loss='mean_squared_error')
model2.summary()
model2.fit(weights,heights,epochs=100)
딥러닝 활용 예시
- 최신 자연어 처리 모델 LLM large language model
- 이미지: 합성곱CNN 연산. 3차원 데이터를 모델에 학습.
- stable diffusion: 텍스트에서 이미지로. multimodal.
실제 데이터로 직접(api 수집 등) 전처리하여 성과 및 액션 아이템을 도출할 수 있도록...
오늘의 교훈; 미리미리 hazar..
잠재성장률: 한 나라가 보유한 모든 생산요소를 사용해 최대한 이룰 수 있는 경제성장률을 의미
(물가 상승은 유발하지 않으며 최대한 성장할 수 있는 수치)
채권
단기채 만기 1년미만
중기채 만기 1~3년
장기채 만기 3년 이상
(현재 시점에서 남은 만기를 기준으로 판별)
신용스프레드: 신용으로 인해 생기는 금리의 차이
장단기스프레드: 만기에 따라 생기는 이자율의 차이
'TIL' 카테고리의 다른 글
| 240207수_TIL (0) | 2024.02.07 |
|---|---|
| 240206화_TIL (1) | 2024.02.06 |
| 240202금_TIL (0) | 2024.02.02 |
| 240201목_TIL (0) | 2024.02.01 |
| 240131수_TIL (0) | 2024.01.31 |




