Classification- Decision Tree / Random Forest Code
import os
import gc
import pickle
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, f1_score
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from collections import Counter
from sklearn import tree# Data Loading (수술 時 사망 데이터)
data = pd.read_csv()
#컬럼 갯수 확인
data.shape[1]
data.describe()
# Label Balace Check - Imbalance
Counter(data['censor'])2배 정도의 imbalance는 괜찮다
# X's & Y Split
Y = data['censor']
X = data.drop(columns=['censor'])
data.shape
X.shape
Y.shape
idx = list(range(X.shape[0]))
train_idx, valid_idx = train_test_split(idx, test_size=0.3, random_state=2023)
print(">>>> # of Train data : {}".format(len(train_idx)))
print(">>>> # of valid data : {}".format(len(valid_idx)))
print(">>>> # of Train data Y : {}".format(Counter(Y.iloc[train_idx])))
print(">>>> # of valid data Y : {}".format(Counter(Y.iloc[valid_idx])))
[Decision Tree를 활용한 Rule Extraction]
- Max_Depth는 5 초과를 넘지 않아야함, 5를 초과하게 되면 Rule Extraction Plotting의 가독성이 매우 떨어짐
- 정확도와 설명력은 Trade-off가 존재하기 때문에 자기만의 기준으로 적절한 선을 선택하면 됨
- Rule Extraction 할때 GINI INDEX 뿐만 아니라 Sample 개수도 중요한 척도가 됨
GINI INDEX가 아주 낮지만(불순도가 낮음, 좋음) Sample의 개수가 너무 적으면 의미가 없음(Overfitting이라고 생각됨)
# Depth 조절 Decision Tree
for i in range(2,11,1):
print(">>>> Depth {}".format(i))
model = DecisionTreeClassifier(max_depth=i, criterion='gini')
model.fit(X.iloc[train_idx], Y.iloc[train_idx])
# Train Acc
y_pre_train = model.predict(X.iloc[train_idx])
cm_train = confusion_matrix(Y.iloc[train_idx], y_pre_train)
print("Train Confusion Matrix")
print(cm_train)
print("Train Acc : {}".format((cm_train[0,0] + cm_train[1,1])/cm_train.sum()))
print("Train F1-Score : {}".format(f1_score(Y.iloc[train_idx], y_pre_train)))
# Test Acc
y_pre_test = model.predict(X.iloc[valid_idx])
cm_test = confusion_matrix(Y.iloc[valid_idx], y_pre_test)
print("Train Confusion Matrix")
print(cm_test)
print("TesT Acc : {}".format((cm_test[0,0] + cm_test[1,1])/cm_test.sum()))
print("Test F1-Score : {}".format(f1_score(Y.iloc[valid_idx], y_pre_test)))
print("-----------------------------------------------------------------------")
print("-----------------------------------------------------------------------")
# Depth가 깊어질 수록 정확도는 높게 나오지만 해석력에 대한 가독성을 위해 Depth 5를 선택함
model = DecisionTreeClassifier(max_depth=4, criterion='gini')
model.fit(X.iloc[train_idx], Y.iloc[train_idx])# Creating the tree plot
tree.plot_tree(model, filled=True, feature_names=X.columns, class_names = ['Dead', 'indicator'])
plt.rcParams['figure.figsize'] = [30,10]
왼 true 오 false
event 901초과 false /지니계수 0.05 /샘플갯수도 고려사항
event 901이하, r 0.5 초과, cd496 161이하 indicator & 샘플갯수 48개 /122개 중 절반 이상
- Hyperparameter tuning
- estimators, depth
- Random Forest는 이 두개만 조절해도 좋은 결과를 얻을 수 있음
- GridSearchCV를 사용하지 않고 For Loop를 돌리는 이유
- 내가 원하는 결과를 저장하고 Display 하고 싶음
- 내가 원하는 결과를 실시간 Display 하면서 그때 그때 파라미터 튜닝에 대한 대처를 하고 싶음
[Random Forest Parameters]
- Package : https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
- n_estimators : # of Tree
- criterion : Measuring for Split (Information gain)
- Gini
- entropy
- log_loss
- max_depth : Tree의 최대 깊이 제한
- min_samples_split : 2개로 Split 하는게 아니라 N개로 Split 가능
- bootstrap : Bagging 중 Boostrap 기법
- max_features : Feature 수 sampling
- auto
- sqrt
- log2
- oob_score : out-of-bag Score
- class_weight : Label Imbalance 데이터 학습시 weight를 주는 것
- {0: 1, 1: 1}
- random_state : Two way Random Choosen 때문에 매 결과가 달라짐
- 지정한 값으로 해주는 것이 결과가 같아짐
# RandomForest Hyperparameter
estimators = [10, 30, 40, 50, 60]
depth = [4 , 5, 10, 15]
# Modeling
save_est = []
save_dep = []
f1_score_ = []
cnt = 0
for est in estimators:
for dep in depth:
print(">>> {} <<<".format(cnt))
cnt += 1
print("Number of Estimators : {}, Max Depth : {}".format(est, dep))
model = RandomForestClassifier(n_estimators=est, max_depth=dep, random_state=119,
criterion='gini', max_features='auto',
bootstrap=True, oob_score=False) # if you use "oob_score=True", get long time for training
model.fit(X.iloc[train_idx], Y.iloc[train_idx])
# Train Acc
y_pre_train = model.predict(X.iloc[train_idx])
cm_train = confusion_matrix(Y.iloc[train_idx], y_pre_train)
print("Train Confusion Matrix")
print(cm_train)
print("Train Acc : {}".format((cm_train[0,0] + cm_train[1,1])/cm_train.sum()))
print("Train F1-Score : {}".format(f1_score(Y.iloc[train_idx], y_pre_train)))
# Test Acc
y_pre_test = model.predict(X.iloc[valid_idx])
cm_test = confusion_matrix(Y.iloc[valid_idx], y_pre_test)
print("Test Confusion Matrix")
print(cm_test)
print("TesT Acc : {}".format((cm_test[0,0] + cm_test[1,1])/cm_test.sum()))
print("Test F1-Score : {}".format(f1_score(Y.iloc[valid_idx], y_pre_test)))
print("-----------------------------------------------------------------------")
print("-----------------------------------------------------------------------")
save_est.append(est)
save_dep.append(dep)
f1_score_.append(f1_score(Y.iloc[valid_idx], y_pre_test))# Best Model
best_model = RandomForestClassifier(n_estimators=save_est[np.argmax(f1_score_)], max_depth=save_dep[np.argmax(f1_score_)], random_state=119,
criterion='gini', max_features='auto',
bootstrap=True, oob_score=False) # if you use "oob_score=True", get long time for training
best_model.fit(X.iloc[train_idx], Y.iloc[train_idx])# Train Acc
y_pre_train = best_model.predict(X.iloc[train_idx])
cm_train = confusion_matrix(Y.iloc[train_idx], y_pre_train)
print("Train Confusion Matrix")
print(cm_train)
print("Train Acc : {}".format((cm_train[0,0] + cm_train[1,1])/cm_train.sum()))
print("Train F1-Score : {}".format(f1_score(Y.iloc[train_idx], y_pre_train)))
# Test Acc
y_pre_test = best_model.predict(X.iloc[valid_idx])
cm_test = confusion_matrix(Y.iloc[valid_idx], y_pre_test)
print("Test Confusion Matrix")
print(cm_test)
print("TesT Acc : {}".format((cm_test[0,0] + cm_test[1,1])/cm_test.sum()))
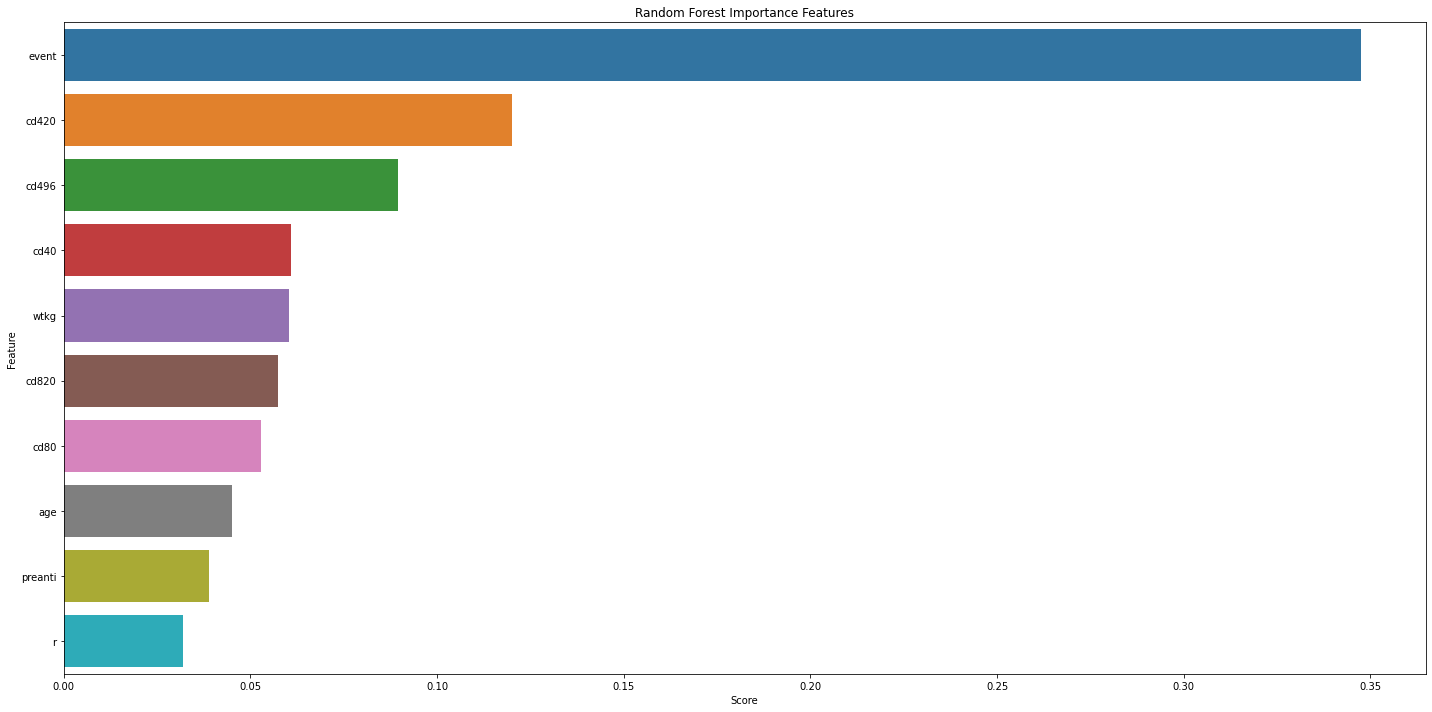
print("Test F1-Score : {}".format(f1_score(Y.iloc[valid_idx], y_pre_test)))feature_map = pd.DataFrame(sorted(zip(best_model.feature_importances_, X.columns), reverse=True), columns=['Score', 'Feature'])
print(feature_map)# Importance Score Top 10
feature_map_20 = feature_map.iloc[:10]
plt.figure(figsize=(20, 10))
sns.barplot(x="Score", y="Feature", data=feature_map_20.sort_values(by="Score", ascending=False), errwidth=40)
plt.title('Random Forest Importance Features')
plt.tight_layout()
plt.show()